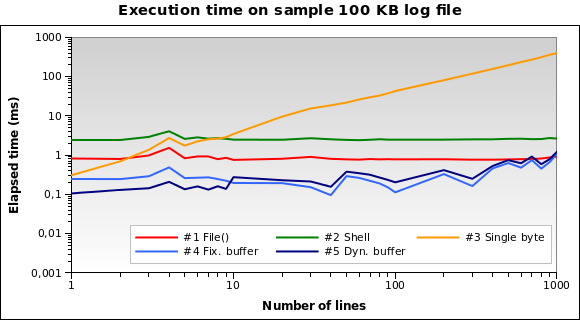
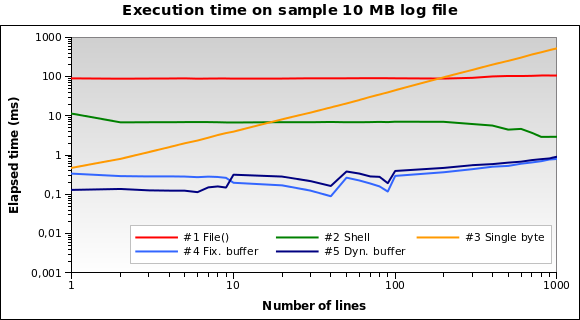
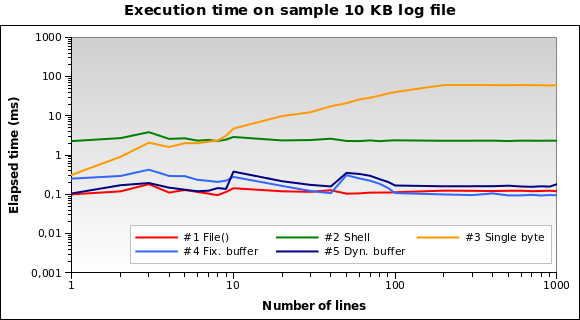
В моем приложении PHP мне нужно прочитать несколько строк, начиная с конца
много файлов (в основном журналы). Иногда мне нужен только последний, иногда мне нужен
десятки или сотни. В принципе, я хочу что-то гибкое, как Unix tail
команда.
Здесь есть вопросы о том, как получить последнюю строку из файла (но Мне нужны N строк), и были даны разные решения. Я не уверен, что один лучший и который лучше работает.