Есть ли простой способ сгладить список итераций с пониманием списка или, если не считать этого, что бы вы считали лучшим способом сгладить мелкий список, подобный этому, балансируя производительность и читаемость?
Я попытался сгладить такой список с помощью вложенного списка, например:
[image for image in menuitem for menuitem in list_of_menuitems]
Но у меня проблемы с разнообразием NameError, потому что name 'menuitem' is not defined. После googling и оглядываясь на Stack Overflow, я получил желаемые результаты с помощью инструкции reduce:
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
Но этот метод довольно непроницаем, потому что мне нужен вызов list(x), потому что x является объектом Django QuerySet.
Заключение:
Спасибо всем, кто внес свой вклад в этот вопрос. Вот краткое изложение того, что я узнал. Я также создаю это сообщество wiki, если другие хотят добавить или исправить эти наблюдения.
Моя первоначальная инструкция сокращения избыточна и лучше написана следующим образом:
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
Это правильный синтаксис для вложенного понимания списка (Brilliant summary dF!):
>>> [image for mi in list_of_menuitems for image in mi]
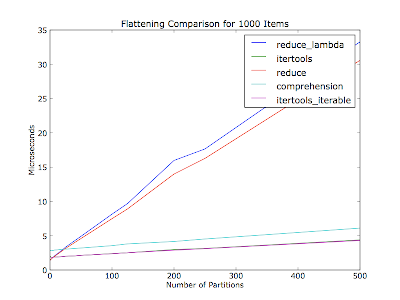
Но ни один из этих методов не эффективен, как использование itertools.chain:
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
И как примечания @cdleary, это, вероятно, лучший стиль, чтобы избежать * магии оператора с помощью chain.from_iterable следующим образом:
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]