Я сохраняю 100.000 векторов в базе данных. Каждый вектор имеет размерность 60. (int vector [60])
Затем я беру один и хочу, чтобы существующие векторы были для пользователя в порядке уменьшения подобия к выбранному.
Я использую Tanimoto Classifier для сравнения 2 векторов:

Есть ли какие-либо методы, чтобы избежать выполнения всех записей в базе данных?
Еще одна вещь! Мне не нужно сортировать все векторы в базе данных. Я хочу получить 20 лучших похожих векторов. Так что, может быть, мы можем примерно порог 60% записей и использовать остальные для сортировки. Как вы думаете?
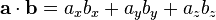
{kind=link}