В библиотеке Akka Streams уже имеется довольно богатая документация . Однако главная проблема для меня заключается в том, что она предоставляет слишком много материала - я чувствую себя совершенно ошеломленным количеством понятий, которые мне нужно изучить. Множество примеров, показанных там, чувствуют себя очень тяжеловесными и не могут быть легко переведены в реальные случаи использования в мире и поэтому весьма эзотеричны. Я думаю, что это дает слишком много деталей, не объясняя, как объединить все строительные блоки и как именно это помогает решить конкретные проблемы.
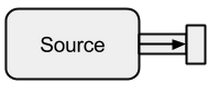
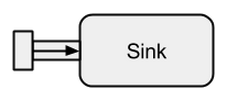
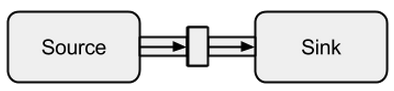
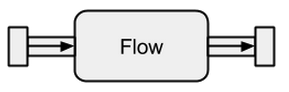
Есть источники, стоки, потоки, этапы графа, частичные графики, материализация, график DSL и многое другое, и я просто не знаю с чего начать. руководство по быстрому запуску должно быть начальным, но я этого не понимаю. Он просто бросает в понятия, упомянутые выше, не объясняя их. Кроме того, примеры кода не могут быть выполнены - отсутствуют недостающие части, что делает более или менее невозможным для меня следовать тексту.
Может ли кто-нибудь объяснить истоки источников, потоки, потоки, этапы графа, частичные графики, материализацию и, возможно, некоторые другие вещи, которые я пропустил простыми словами и с легкими примерами, которые не объясняют каждую деталь (и которые, вероятно, не являются необходимо в любом случае в начале)?