Я пытаюсь использовать регулярное выражение в Python для поиска и печати всех соответствующих строк из многострочного поиска. Текст, который я просматриваю, может иметь следующую структуру:
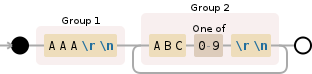
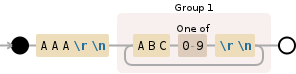
AAA ABC1 ABC2 ABC3 AAA ABC1 ABC2 ABC3 ABC4 ABC AAA ABC1 AAA
Из которого я хочу получить ABC * s, которые происходят по крайней мере один раз и предшествуют AAA.
Проблема в том, что, несмотря на то, что группа ломает то, что я хочу:
match = <_sre.SRE_Match object; span=(19, 38), match='AAA\nABC2\nABC3\nABC4\n'>
... Я могу получить доступ только к последнему совпадению группы:
match groups = ('AAA\n', 'ABC4\n')
Ниже приведен пример кода, который я использую для этой проблемы.
#! python
import sys
import re
import os
string = "AAA\nABC1\nABC2\nABC3\nAAA\nABC1\nABC2\nABC3\nABC4\nABC\nAAA\nABC1\nAAA\n"
print(string)
p_MATCHES = []
p_MATCHES.append( (re.compile('(AAA\n)(ABC[0-9]\n){1,}')) ) #
matches = re.finditer(p_MATCHES[0],string)
for match in matches:
strout = ''
gr_iter=0
print("match = "+str(match))
print("match groups = "+str(match.groups()))
for group in match.groups():
gr_iter+=1
sys.stdout.write("TEST GROUP:"+str(gr_iter)+"\t"+group) # test output
if group is not None:
if group != '':
strout+= '"'+group.replace("\n","",1)+'"'+'\n'
sys.stdout.write("\nCOMPLETE RESULT:\n"+strout+"====\n")