Регулярные выражения могут стать довольно сложными. Отсутствие пробелов затрудняет их чтение. Я не могу шагнуть, хотя регулярное выражение с отладчиком. Итак, как эксперты отлаживают сложные регулярные выражения?
Как вы отлаживаете регулярное выражение?
Ответ 1
Вы покупаете RegexBuddy и используете его встроенный debug особенность. Если вы работаете с регулярными выражениями более двух раз в год, вы вернете эти деньги вовремя, сохраненные в кратчайшие сроки. RegexBuddy также поможет вам создавать простые и сложные регулярные выражения и даже генерировать код для вас на разных языках.
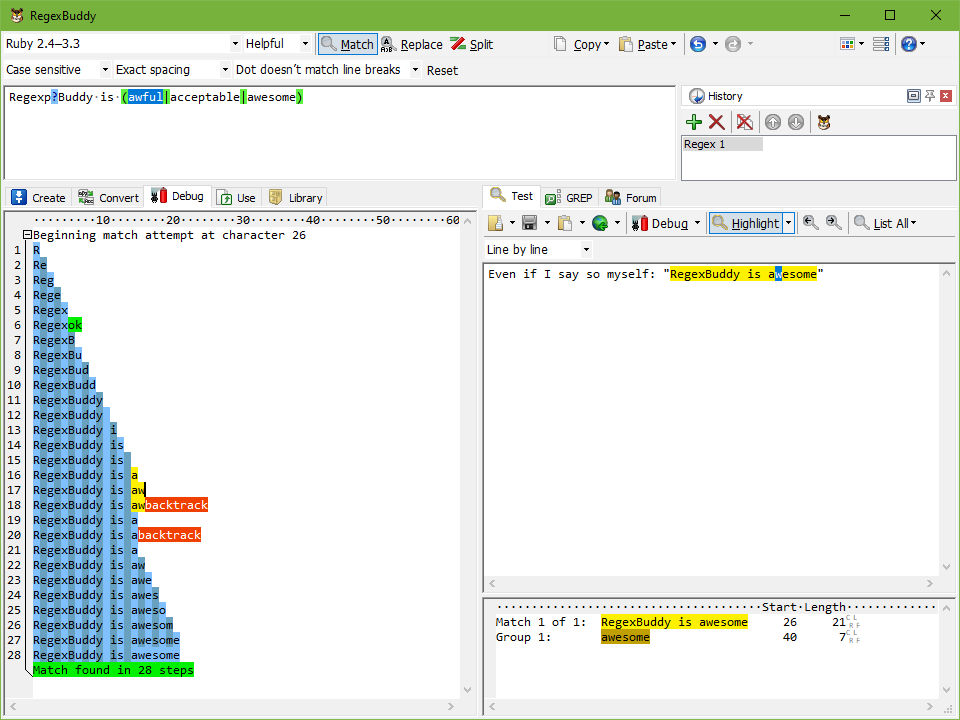
Кроме того, по словам разработчика, этот инструмент работает почти безупречно на Linux при использовании с WINE.
Ответ 2
С Perl 5.10, use re 'debug';. (Или debugcolor, но я не могу правильно отформатировать вывод в Stack Overflow.)
$ perl -Mre=debug -e'"foobar"=~/(.)\1/'
Compiling REx "(.)\1"
Final program:
1: OPEN1 (3)
3: REG_ANY (4)
4: CLOSE1 (6)
6: REF1 (8)
8: END (0)
minlen 1
Matching REx "(.)\1" against "foobar"
0 <> <foobar> | 1:OPEN1(3)
0 <> <foobar> | 3:REG_ANY(4)
1 <f> <oobar> | 4:CLOSE1(6)
1 <f> <oobar> | 6:REF1(8)
failed...
1 <f> <oobar> | 1:OPEN1(3)
1 <f> <oobar> | 3:REG_ANY(4)
2 <fo> <obar> | 4:CLOSE1(6)
2 <fo> <obar> | 6:REF1(8)
3 <foo> <bar> | 8:END(0)
Match successful!
Freeing REx: "(.)\1"
Кроме того, вы можете добавлять пробелы и комментарии к регулярным выражениям, чтобы сделать их более читаемыми. В Perl это делается с помощью модификатора /x. С pcre существует флаг PCRE_EXTENDED.
"foobar" =~ /
(.) # any character, followed by a
\1 # repeat of previously matched character
/x;
pcre *pat = pcre_compile("(.) # any character, followed by a\n"
"\\1 # repeat of previously matched character\n",
PCRE_EXTENDED,
...);
pcre_exec(pat, NULL, "foobar", ...);
Ответ 3
Я добавлю еще один, чтобы не забыть: debuggex
Это хорошо, потому что это очень визуально: 
Ответ 4
Когда я застреваю в регулярном выражении, я обычно обращаюсь к этому: https://regexr.com/
Это идеально подходит для быстрого тестирования, где что-то идет не так.
Ответ 5
Я использую Kodos - отладчик регулярных выражений Python:
Kodos - это утилита Python GUI для создания, тестирования и отладки регулярных выражений для языка программирования Python. Kodos должен помочь любому разработчику эффективно и без усилий разрабатывать регулярные выражения в Python. Поскольку реализация регулярных выражений в Python основана на стандарте PCRE, Kodos должен помочь разработчикам на других языках программирования, которые также придерживаются стандарта PCRE (Perl, PHP и т.д.).
(...)

Работает на Linux, Unix, Windows, Mac.
Ответ 6
Я думаю, что нет. Если ваше регулярное выражение является слишком сложным и проблематичным до такой степени, что вам нужен отладчик, вы должны создать конкретный синтаксический анализатор или использовать другой метод. Он будет гораздо читабельнее и удобнее.
Ответ 7
Существует отличный бесплатный инструмент, тренер Regex. Последняя версия доступна только для Windows; его автор доктор Эдмунд Вейц прекратил поддерживать версию Linux, потому что слишком мало людей загрузило ее, но на странице загрузки есть более ранняя версия для Linux.
Ответ 8
Я только что видел презентацию Regexp:: Debugger ее создателем: Дамиан Конвей. Очень впечатляющие вещи: запускать inplace или использовать инструмент командной строки (rxrx), интерактивно или в "зарегистрированном" исполняемом файле (хранящемся в JSON), переходить вперёд и назад в любую точку, останавливаться на контрольных точках или событиях, цветной вывод (настраиваемый пользователем), тепловые карты по регулярному выражению и строке для оптимизации и т.д.
Доступно на CPAN бесплатно: http://search.cpan.org/~dconway/Regexp-Debugger/lib/Regexp/Debugger.pm
Ответ 9
Я использую этот онлайн-инструмент для отладки моего регулярного выражения:
Но да, он не может победить RegexBuddy.
Ответ 10
Я отлаживаю свои регулярные выражения своими глазами. Поэтому я использую модификатор /x, пишу для них комментарии и делю их на части. Прочтите Джеффри Фридла " Освоение регулярных выражений", чтобы узнать, как разрабатывать быстрые и удобочитаемые регулярные выражения. Различные инструменты отладки регулярных выражений просто провоцируют программирование вуду.
Ответ 11
Как и для меня, я обычно использую утилиту pcretest, которая может сбрасывать байтовый код любого регулярного выражения, и, как правило, его гораздо легче читать (по крайней мере для меня). Пример:
PCRE version 8.30-PT1 2012-01-01
re> /ab|c[de]/iB
------------------------------------------------------------------
0 7 Bra
3 /i ab
7 38 Alt
10 /i c
12 [DEde]
45 45 Ket
48 End
------------------------------------------------------------------
Ответ 12
Я использую:
http://regexlib.com/RETester.aspx
Вы также можете попробовать Regex Hero (использует Silverlight):
Ответ 13
Если я чувствую себя застрявшим, мне нравится возвращаться и генерировать регулярное выражение непосредственно из образца текста, используя txt2re (хотя Я обычно в конечном итоге настраиваю полученное регулярное выражение вручную).
Ответ 14
Если вы пользователь Mac, я просто натолкнулся на это:
http://atastypixel.com/blog/reginald-regex-explorer/
Это бесплатное и простое в использовании, и мне очень помогло справиться с RegExs в целом.
Ответ 15
Посмотрите на инструменты (non-free) на regular-expressions.info. RegexBuddy в частности. Вот сообщение Джеффа Этвуда по теме.
Ответ 16
Запись реестров с использованием нотации, такой как PCRE, похожа на запись ассемблера: это прекрасно, если вы можете просто увидеть соответствующие автоматы с конечным состоянием в голове, но это может быть трудно поддерживать очень быстро.
Причины отказа от использования отладчика - это то же самое, что и не использовать отладчик с языком программирования: вы можете исправить локальные ошибки, но они не помогут вам решить проблемы с дизайном, которые привели вас к локальным ошибкам в первую очередь.
Более рефлексивный способ - использовать представления данных для генерации регулярных выражений на вашем языке программирования и иметь соответствующие абстракции для их создания. Введение Olin Shiver в его схему regexp notation дает отличный обзор проблем, возникающих при проектировании этих представлений данных.
Ответ 17
Я часто использую pcretest - вряд ли "отладчик", но он работает над текстовым SSH-соединением и анализирует точно нужный диалект регулярного выражения: мои (С++) ссылки на libpcre, поэтому нет никаких трудностей с тонкими различиями в том, что магия, а что нет, и т.д.
В общем, я согласен с парнем выше, которому нужен отладчик регулярных выражений - это запах кода. Для меня труднее всего использовать регулярные выражения, как правило, не самого регулярного выражения, а несколько слоев цитирования, необходимых для их работы.
Ответ 18
Я часто использую Ruby regexp tester Rubular
а также в Emacs используйте M-x re-builder
В Firefox также есть полезное расширение
Ответ 19
Я использую Rx Toolkit, который включен в ActiveState Komodo.
Ответ 20
Вы можете попробовать это http://www.pagecolumn.com/tool/regtest.htm
Ответ 21
Для меня, после того, как я просмотрел регулярное выражение (поскольку я довольно свободно владею и почти всегда использую /x или эквивалент), я мог бы отлаживать, а не тестировать, если я не уверен, ударил бы я несколько вырожденных соответствий (то есть что-то, что чрезмерное отставание), чтобы увидеть, могу ли я решить такие проблемы, например, изменив жадность оператора.
Чтобы сделать это, я бы использовал один из методов, упомянутых выше: pcretest, RegexBuddy (если мое текущее рабочее место лицензировало его) или подобное, и иногда я использую его в Linqpad, если я работаю в регулярных выражениях С#.
(Perl-трюк для меня новый, поэтому, вероятно, это добавит и к моему инструменту regex).