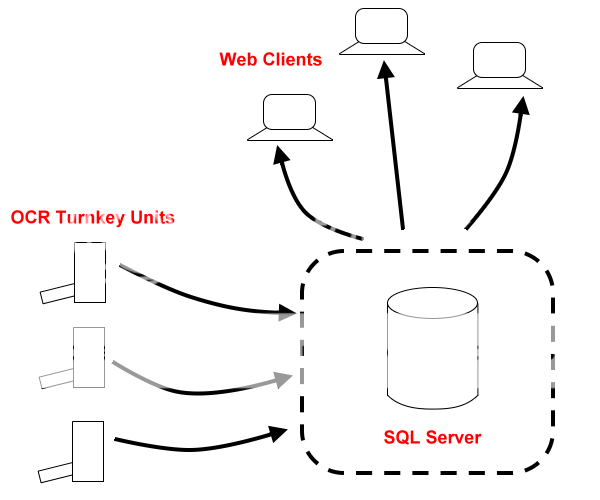
Я работаю в медицинской лаборатории. Они должны иметь возможность выполнять поиск по всем своим клиентским данным. Пока у них есть несколько лет хранения около 4 миллионов листов бумаги, и они добавляют 10 000 страниц в день. Для данных, которым 6 месяцев, они должны получить к нему доступ примерно 10-20 раз в день. Они решают, тратить ли 80k на сканирующую систему и секретари сканировать все в доме или нанимать компанию, такую как железная гора, для этого. Железная гора будет взимать около 8 центов за страницу, что составляет около 300 тысяч долларов за количество бумаги, которую мы имеем, плюс еще кучу денег каждый день за 10 000 листов.
Я думаю, что, возможно, я смогу создать базу данных и сделать все сканирование в доме.
- Что такое те системы, которые используются для проверки чеков и почты, и они действительно хорошо читают действительно грязную ручную запись?
- У кого-нибудь есть опыт создания базы данных с набором доступных для поиска документов OCR'd? Какие инструменты следует использовать для моей проблемы?
- Вы можете рекомендовать лучшие библиотеки OCR?
- Как программист, что бы вы сделали для решения этой проблемы?
FYI ни один из ответов ниже не отвечает на мои вопросы достаточно хорошо