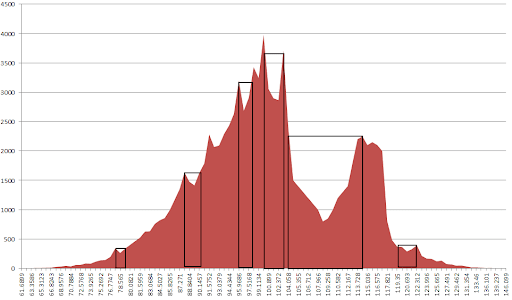
Мне интересно найти локальные минимумы в гистограмме, которая примерно напоминает

Я бы хотел найти локальный минимум на уровне 109.258, и самый простой способ сделать это - определить, будет ли количество отсчетов в 109.258 ниже среднего числа отсчетов вокруг в некотором интервале (включая 109.258). Это определяет этот интервал, который является самой трудной для меня частью.
Что касается источника этих данных, то это гистограмма со 100 бункерами неравномерной ширины. Каждый бит имеет значение (показано на оси x) и количество образцов, попадающих в этот бункер (показано на оси y). То, что я пытаюсь сделать, - найти "лучшее" место для разделения гистограммы. Каждая сторона раскола распространяется по двоичному дереву как часть алгоритма классификации.
Я думаю, что мой лучший способ действий - попытаться подогнать кривую к этой гистограмме, используя что-то вроде алгоритм Левенберга-Марквардта, а затем сравнить локальные минимумы, чтобы найти "лучший". Правильная мера "наилучшего" будет включать некоторые признаки значимости этого раскола, который измеряется как разница между средними значениями в интервале слева и средним числом отсчетов в интервале справа, а затем, возможно, вес каждой разницы с количеством включенных отсчетов, чтобы получить составное измерение "лучше", если это имеет смысл.
В любом случае вычислительная сложность алгоритма не является огромной проблемой, 100 бит - это максимальное число, которое я ожидал бы встретить. Однако этот расчет будет выполняться один раз для каждого образца, поэтому сохранение его линейного относительно количества ящиков, конечно, было бы идеальным.
Кстати, я делаю все на С++ и использую библиотеки boost и STL, поэтому в этом отношении ничего не выходит.
Любые мысли или идеи, касающиеся наилучшей практики, будут очень признательны!