Есть ли у кого-нибудь информация о характеристиках производительности буферов протокола против BSON (двоичный JSON) или в сравнении с JSON вообще?
- Размер провода
- Скорость сериализации
- Скорость десериализации.
Они кажутся хорошими бинарными протоколами для использования через HTTP. Мне просто интересно, что было бы лучше в долгосрочной перспективе для среды С#.
Вот некоторая информация, которую я читал на BSON и Protocol Буферы.

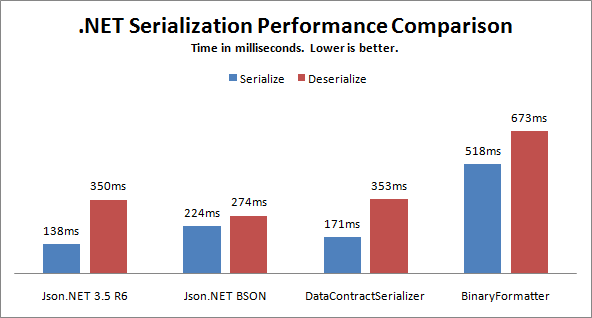{kind=link}
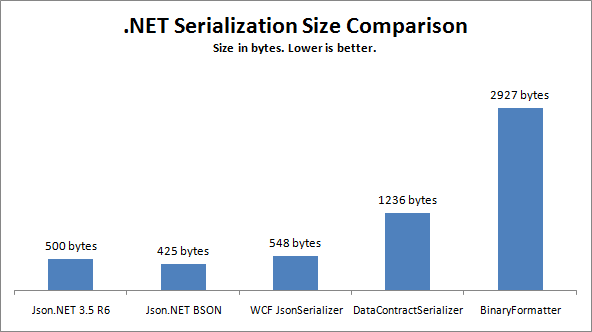{kind=link}