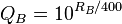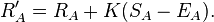Я хотел бы оценивать коллекцию пейзажных изображений, создавая игру, в которой посетители сайта могут оценивать их, чтобы узнать, какие изображения люди находят наиболее привлекательными.
Что было бы хорошим способом сделать это?
- Стиль Hot-or-Not? То есть показать одно изображение, попросить пользователя оценить его с 1-10. Как я вижу, это позволяет мне усреднять баллы, и мне просто нужно будет обеспечить равномерное распределение голосов по всем изображениям. Довольно просто реализовать.
- Выбрать A-or-B? То есть показать два изображения, попросить пользователя выбрать лучший. Это привлекательно, поскольку нет численного рейтинга, это просто сравнение. Но как мне его реализовать? Моя первая мысль заключалась в том, чтобы сделать это как быструю сортировку, при этом операции сравнения были предоставлены людьми, и как только они закончились, просто повторите сортировку ad-infinitum.
Как вы это сделаете?
Если вам нужны номера, я говорю об одном миллионе изображений, на сайте с 20 000 ежедневных посещений. Я бы предположил, что небольшая часть может сыграть в игру, ради аргумента, скажем, я могу генерировать 2000 человеческих операций в день! Это некоммерческий веб-сайт, и неизлечимо любопытный найдет его через мой профиль:)