В попытке взглянуть на это, я написал этот простой код, где я просто создал переменные разных типов и передал их в функцию по значению, по ссылке и по указателю:
int i = 1;
char c = 'a';
int* p = &i;
float f = 1.1;
TestClass tc; // has 2 private data members: int i = 1 and int j = 2
тела функций остались пустыми, потому что я просто смотрю, как передаются параметры.
passByValue(i, c, p, f, tc);
passByReference(i, c, p, f, tc);
passByPointer(&i, &c, &p, &f, &tc);
хотел посмотреть, как это отличается для массива, а также как параметры доступа к ним.
int numbers[] = {1, 2, 3};
passArray(numbers);
монтаж:
passByValue(i, c, p, f, tc)
mov EAX, DWORD PTR [EBP - 16]
mov DL, BYTE PTR [EBP - 17]
mov ECX, DWORD PTR [EBP - 24]
movss XMM0, DWORD PTR [EBP - 28]
mov ESI, DWORD PTR [EBP - 40]
mov DWORD PTR [EBP - 48], ESI
mov ESI, DWORD PTR [EBP - 36]
mov DWORD PTR [EBP - 44], ESI
lea ESI, DWORD PTR [EBP - 48]
mov DWORD PTR [ESP], EAX
movsx EAX, DL
mov DWORD PTR [ESP + 4], EAX
mov DWORD PTR [ESP + 8], ECX
movss DWORD PTR [ESP + 12], XMM0
mov EAX, DWORD PTR [ESI]
mov DWORD PTR [ESP + 16], EAX
mov EAX, DWORD PTR [ESI + 4]
mov DWORD PTR [ESP + 20], EAX
call _Z11passByValueicPif9TestClass
passByReference(i, c, p, f, tc)
lea EAX, DWORD PTR [EBP - 16]
lea ECX, DWORD PTR [EBP - 17]
lea ESI, DWORD PTR [EBP - 24]
lea EDI, DWORD PTR [EBP - 28]
lea EBX, DWORD PTR [EBP - 40]
mov DWORD PTR [ESP], EAX
mov DWORD PTR [ESP + 4], ECX
mov DWORD PTR [ESP + 8], ESI
mov DWORD PTR [ESP + 12], EDI
mov DWORD PTR [ESP + 16], EBX
call _Z15passByReferenceRiRcRPiRfR9TestClass
passByPointer(&i, &c, &p, &f, &tc)
lea EAX, DWORD PTR [EBP - 16]
lea ECX, DWORD PTR [EBP - 17]
lea ESI, DWORD PTR [EBP - 24]
lea EDI, DWORD PTR [EBP - 28]
lea EBX, DWORD PTR [EBP - 40]
mov DWORD PTR [ESP], EAX
mov DWORD PTR [ESP + 4], ECX
mov DWORD PTR [ESP + 8], ESI
mov DWORD PTR [ESP + 12], EDI
mov DWORD PTR [ESP + 16], EBX
call _Z13passByPointerPiPcPS_PfP9TestClass
passArray(numbers)
mov EAX, .L_ZZ4mainE7numbers
mov DWORD PTR [EBP - 60], EAX
mov EAX, .L_ZZ4mainE7numbers+4
mov DWORD PTR [EBP - 56], EAX
mov EAX, .L_ZZ4mainE7numbers+8
mov DWORD PTR [EBP - 52], EAX
lea EAX, DWORD PTR [EBP - 60]
mov DWORD PTR [ESP], EAX
call _Z9passArrayPi
// parameter access
push EAX
mov EAX, DWORD PTR [ESP + 8]
mov DWORD PTR [ESP], EAX
pop EAX
Я предполагаю, что я смотрю на правильную сборку, связанную с передачей параметра, потому что в конце каждого из них есть вызовы!
Но из-за моих очень ограниченных знаний об собраниях я не могу сказать, что происходит здесь. Я узнал о конвенции ccall, поэтому я предполагаю, что что-то происходит, что связано с сохранением регистров, сохраненных вызывающим абонентом, а затем путем нажатия параметров в стек. Из-за этого я ожидаю, что все вещи загрузятся в регистры и "нажимают" всюду, но не имеют представления о том, что происходит с mov и lea s. Кроме того, я не знаю, что такое DWORD PTR.
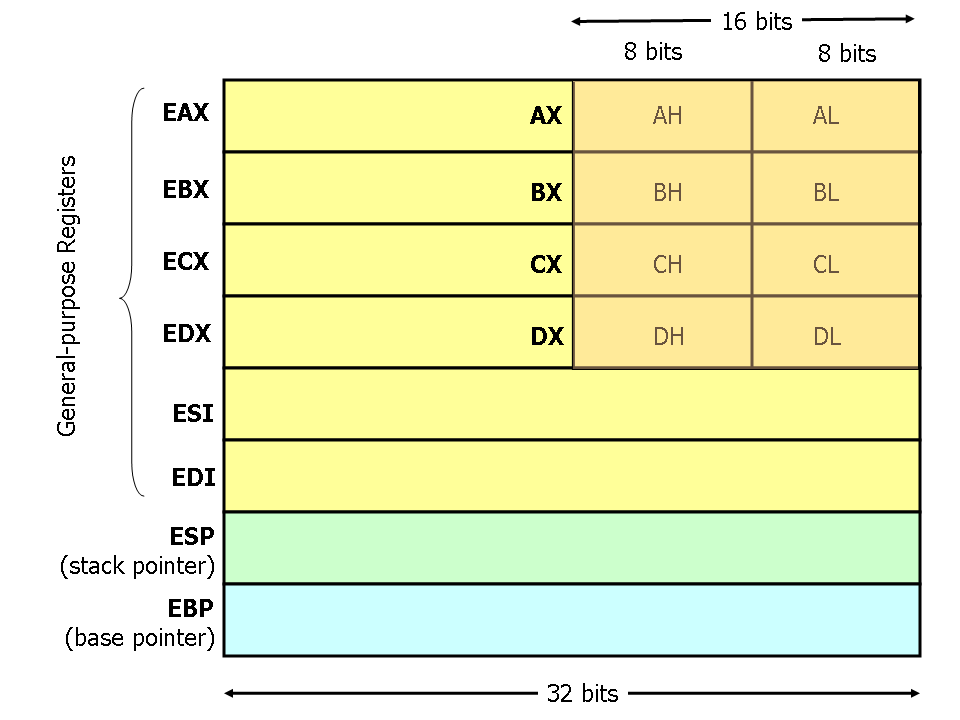
Я только узнал о регистрах: eax, ebx, ecx, edx, esi, edi, esp и ebp, поэтому просмотр чего-то вроде XMM0 или DL просто смущает меня. Я думаю, имеет смысл видеть lea когда дело доходит до передачи по ссылке/указателю, потому что они используют адреса памяти, но я не могу сказать, что происходит. Когда дело доходит до передачи по значению, кажется, что существует множество инструкций, поэтому это может быть связано с копированием значения в регистры. Не знаю, когда дело доходит до того, как массивы передаются и доступны как параметры.
Если бы кто-то мог объяснить общее представление о том, что происходит с каждым блоком сборки, я бы очень признателен.
{kind=link}