Может ли кто-нибудь объяснить это утверждение:
shared variables
x = 0, y = 0
Core 1 Core 2
x = 1; y = 1;
r1 = y; r2 = x;
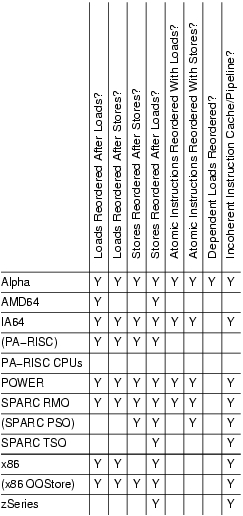
Как возможно иметь r1 == 0 и r2 == 0 на процессорах x86?
Источник "Язык Concurrency" от Bartosz Milewski.
{kind=link}