Как вы прослеживаете путь поиска по ширине, так что в следующем примере:
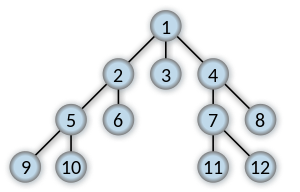
Если вы ищете ключ 11, верните самый короткий список, соединяющий 1 - 11.
[1, 4, 7, 11]
Как вы прослеживаете путь поиска по ширине, так что в следующем примере:
Если вы ищете ключ 11, верните самый короткий список, соединяющий 1 - 11.
[1, 4, 7, 11]
Сначала вы должны взглянуть на http://en.wikipedia.org/wiki/Breadth-first_search.
Ниже приведена быстрая реализация, в которой я использовал список списка для представления очереди путей.
# graph is in adjacent list representation
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def bfs(graph, start, end):
# maintain a queue of paths
queue = []
# push the first path into the queue
queue.append([start])
while queue:
# get the first path from the queue
path = queue.pop(0)
# get the last node from the path
node = path[-1]
# path found
if node == end:
return path
# enumerate all adjacent nodes, construct a new path and push it into the queue
for adjacent in graph.get(node, []):
new_path = list(path)
new_path.append(adjacent)
queue.append(new_path)
print bfs(graph, '1', '11')
Другим подходом было бы сохранение отображения из каждого node его родительскому элементу, а при проверке смежного node запись его родителя. Когда поиск выполняется, просто обратная трассировка соответствует родительскому сопоставлению.
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def backtrace(parent, start, end):
path = [end]
while path[-1] != start:
path.append(parent[path[-1]])
path.reverse()
return path
def bfs(graph, start, end):
parent = {}
queue = []
queue.append(start)
while queue:
node = queue.pop(0)
if node == end:
return backtrace(parent, start, end)
for adjacent in graph.get(node, []):
parent[adjacent] = node # <<<<< record its parent
queue.append(adjacent)
print bfs(graph, '1', '11')
Вышеприведенные коды основаны на предположении, что нет циклов.
Мне очень понравился первый ответ qiao!
Единственное, что отсутствует здесь, - это отметить вершины, которые были посещены.
Зачем нам это нужно?
Предположим, что есть еще один номер node номер 13, подключенный из node 11. Теперь наша цель - найти node 13.
После небольшого пробега очередь будет выглядеть так:
[[1, 2, 6], [1, 3, 10], [1, 4, 7], [1, 4, 8], [1, 2, 5, 9], [1, 2, 5, 10]]
Обратите внимание, что есть два пути с node числом 10. В конце.
Это означает, что пути от node номер 10 будут проверяться дважды. В этом случае это не выглядит так плохо, потому что node номер 10 не имеет детей.. Но это может быть очень плохо (даже здесь мы будем проверять, что node дважды без причины..)
Node номер 13 не находится в этих путях, поэтому программа не вернется, прежде чем перейти ко второму пути с номером node номер 10 в конце. И мы его перепроверем..
Все, что нам не хватает, это набор, чтобы пометить посещаемые узлы и не проверять их снова.
Это код qiao после модификации:
graph = {
1: [2, 3, 4],
2: [5, 6],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs(graph_to_search, start, end):
queue = [[start]]
visited = set()
while queue:
# Gets the first path in the queue
path = queue.pop(0)
# Gets the last node in the path
vertex = path[-1]
# Checks if we got to the end
if vertex == end:
return path
# We check if the current node is already in the visited nodes set in order not to recheck it
elif vertex not in visited:
# enumerate all adjacent nodes, construct a new path and push it into the queue
for current_neighbour in graph_to_search.get(vertex, []):
new_path = list(path)
new_path.append(current_neighbour)
queue.append(new_path)
# Mark the vertex as visited
visited.add(vertex)
print bfs(graph, 1, 13)
Выходной сигнал программы будет:
[1, 4, 7, 11, 13]
Без переустановки без проверки.
Я думал, что попробую код для удовольствия:
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def bfs(graph, forefront, end):
# assumes no cycles
next_forefront = [(node, path + ',' + node) for i, path in forefront if i in graph for node in graph[i]]
for node,path in next_forefront:
if node==end:
return path
else:
return bfs(graph,next_forefront,end)
print bfs(graph,[('1','1')],'11')
# >>>
# 1, 4, 7, 11
Если вы хотите использовать циклы, вы можете добавить это:
for i, j in for_front: # allow cycles, add this code
if i in graph:
del graph[i]
Мне нравится как первый ответ Qiao, так и дополнение. Ради немного меньше обработки я хотел бы добавить к Or ответ.
В или ответе, что отслеживание посещенных node велико. Мы также можем позволить программе выйти раньше, чем она есть. В какой-то момент цикла for current_neighbour должен быть end, и как только это произойдет, найден самый короткий путь и программа может вернуться.
Я бы изменил метод следующим образом: обратите внимание на цикл for
graph = {
1: [2, 3, 4],
2: [5, 6],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs(graph_to_search, start, end):
queue = [[start]]
visited = set()
while queue:
# Gets the first path in the queue
path = queue.pop(0)
# Gets the last node in the path
vertex = path[-1]
# Checks if we got to the end
if vertex == end:
return path
# We check if the current node is already in the visited nodes set in order not to recheck it
elif vertex not in visited:
# enumerate all adjacent nodes, construct a new path and push it into the queue
for current_neighbour in graph_to_search.get(vertex, []):
new_path = list(path)
new_path.append(current_neighbour)
queue.append(new_path)
#No need to visit other neighbour. Return at once
if current_neighbour == end
return new_path;
# Mark the vertex as visited
visited.add(vertex)
print bfs(graph, 1, 13)
Выход и все остальное будут одинаковыми. Однако для обработки кода потребуется меньше времени. Это особенно полезно для больших графиков. Надеюсь, это поможет кому-то в будущем.